Highly Nonlinear Approximations for Sparse Signal Representation

Next: Numerical Simulation Up: Sparse representation by minimization Previous: Sparse representation by minimization
Managing the constraints
Without loss of generality we assume here that the measurements on the signal in hand are given by the values the signal takes at the sampling points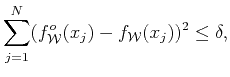
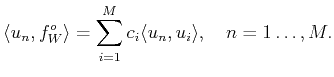
Of course, since we are concerned with ill posed problems we cannot use all these equations to find the coefficients
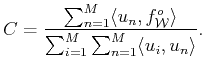 |
(32) |
With this initial estimation we `predict' the normal equations (31) and select as our first constraint the worst predicted by the initial solution, let this equation be the
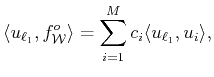 |
(33) |
and indicate the resulting coefficients as
The numerical example discussed next has been solved by recourse to the method for minimization of the ![]() -norm)
-norm)![]() published in
[16]. Such an iterative method, called FOCal Underdetermined
System Solver (FOCUSS) in that publication,
is straightforward implementable. It
evolves by computation of pseudoinverse matrices, which
under the given hypothesis of our problem, and within
our recursive strategy for feeding the constraints,
are guaranteed to be numerically stable
(for a detailed explanation of the method see [16]).
The routine for implementing the proposed strategy
is ALQMin.m.
published in
[16]. Such an iterative method, called FOCal Underdetermined
System Solver (FOCUSS) in that publication,
is straightforward implementable. It
evolves by computation of pseudoinverse matrices, which
under the given hypothesis of our problem, and within
our recursive strategy for feeding the constraints,
are guaranteed to be numerically stable
(for a detailed explanation of the method see [16]).
The routine for implementing the proposed strategy
is ALQMin.m.
Subsections

This project is supported by EPSRC (EP/D062632/1)
